AI Memory Meets Real-World Testing: Rethinking Traditional QA Benchmarks
Evaluating the performance of AI memory systems isn’t straightforward. The usual benchmarks for language models—Exact Match, F1, and even multi-hop QA datasets—weren’t designed to measure what matters most about persistent AI memory: connecting concepts across time, documents, and contexts.
We just completed our most extensive internal evaluation of cognee to date, using HotPotQA as a baseline. While the results showed strong gains, they also reinforced a growing realization: we need better ways to evaluate how AI memory systems actually perform.
In this post, we’ll break down what we measured, how we did it, and why the next generation of benchmarks has to evolve—not just for us, but for the entire AI memory space.
From QA to Memory: What We Tested and Why
Why HotPotQA?
HotPotQA is a benchmark designed for multi-hop reasoning. We chose it because it goes beyond traditional single-document QA by requiring reasoning that combines information from multiple parts of a text.
But even HotPotQA has limits: its reasoning still occurs within narrow, predefined contexts. AI memory systems like cognee are built to operate across timelines, files, and knowledge sources—the kind of open-ended reasoning real-world teams depend on.
Our Setup: 45 Runs, 24 Questions, 3 Competitors
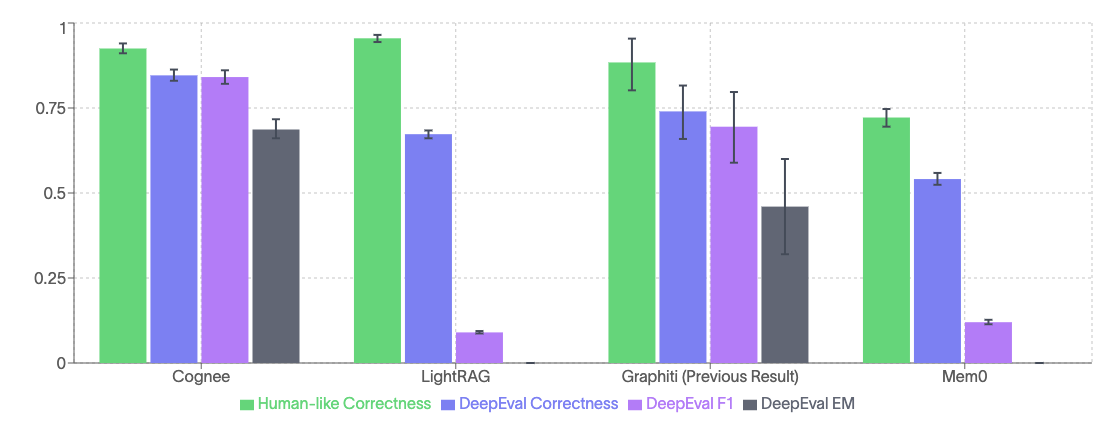
We ran Cognee through 45 evaluation cycles on 24 questions from HotPotQA, using ChatGPT 4o for the analysis. Each part of the evaluation process is affected by the inherent variance in GPT’s output: cognification, answer generation, and answer evaluation. We especially noticed significant variance across different metrics on small runs, which is why we chose the repeated, end-to-end approach.
We compared results using the same questions and setup with:
- Mem0
- Lightrag
- Graphiti (we were not able to run their system, so we are including numbers they shared with us previously, on a smaller-scale study)
How We Measured Performance
We used four metrics to get a fuller picture of how well each system performed:
-
Exact Match (EM)
Binary score for perfect, letter-level matches to the reference answer.
-
F1 Score
Measures word-level overlap between the system’s answer and the reference.
-
DeepEval Correctness
LLM-based grading of semantic accuracy. Useful, but prone to variance—we found that without manual tweaks, the scores weren’t always reflecting the actual correctness of the generated answer.
-
Human-like Correctness
With repeated evaluations, full human-in-the-loop evaluation of each question across all products was not an option. So, we created a simple, LLM-based evaluation, that we believe best approximates the actual human evaluations. We treat this as the lower bound of actual answer quality.
As you can see in the graphs, cognee consistently outperformed the other three platforms across all metrics. Its ability to connect concepts across contexts—thanks to our open-source chain-of-thought retriever—was especially effective in multi-hop scenarios.
Why Traditional QA Metrics Fall Short
1. EM and F1 Don’t Capture Meaning
While they are standard in QA, EM and F1 scores reward surface-level overlap and miss the core value proposition of AI memory systems. For example, a syntactically perfect answer can be factually wrong, and a fuzzy-but-correct response can be penalized for missing the reference phrasing.
Neither of these scores is a great proxy for the actual information content. They’re useful—but insufficient for evaluating reasoning or memory.
2. LLM Scoring is Inconsistent
LLMs are inherently non-deterministic. That means:
- The same output might receive different scores on different runs.
- Evaluation itself becomes noisy, especially on small datasets.
- You need multiple runs and bootstrap sampling just to get a reliable average.
3. The Benchmark is Inapt
Even HotPotQA assumes all relevant information sits neatly in two paragraphs. That’s not how memory works. Real-world AI memory systems need to link information across documents, conversations, and knowledge domains that traditional QA benchmarks just can’t capture.
Consider the difference:
Traditional QA:
“What year was the company that acquired X founded?”
Memory Challenge:
“How do the concerns raised in last month’s security review relate to the authentication changes discussed in the architecture meeting three weeks ago?”
Only one of these tests long-term knowledge, reasoning across sources, and organizational memory—care to guess which one?
The Path Forward: Building a Better Evaluation Framework
Moving Beyond HotPotQA
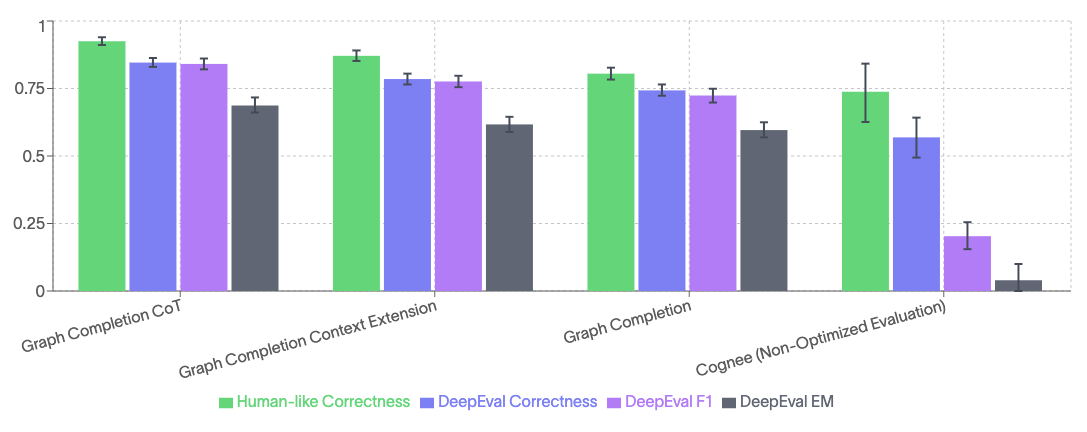
While HotPotQA served as a useful baseline—especially for testing multi-hop reasoning—it's ultimately limited in scope. It doesn't reflect the full range of what AI memory systems are built for: connecting fragmented information across long time spans, evolving contexts, and diverse sources.
We’re moving beyond traditional QA-style datasets and metrics to design evaluations that better reflect the actual utility of AI in real-world use.
A New Dataset Tailored for AI Memory
We’ve developed a new evaluation dataset specifically for AI memory systems. Unlike isolated question-answer pairs, it tests:
- Cross-context linking – Can the system associate relevant information scattered across documents, meetings, and messages?
- Relational understanding – Does it recognize nuanced relationships between concepts beyond simple keyword matching?
- Temporal reasoning – Can it track how facts evolve over time and account for that in answers?
- Multi-step inference – Can it chain reasoning across multiple sources and knowledge domains?
Drawing on these criteria, our dataset creates a more accurate picture of how well memory-enabled systems like cognee perform in practical, high-context environments.
Partnering with DeepEval to Raise the Bar
We’re collaborating with the team over at DeepEval to release this new dataset publicly. Our goal is to provide the AI research and developer communities with tools that truly test what modern memory systems are capable of.
This dataset will include:
- Multi-document reasoning tasks
- Temporal knowledge-evolution challenges
- Cross-domain relationship-inference tests
- Long-context memory-consistency evaluations
By making this open-source, we hope to drive better evaluations across the entire ecosystem of memory-based AI tools—not just our own.
Why This Matters for AI Memory Development
Conventional Evaluation Misses the Point
Most AI benchmarks today focus on getting the right answer once, in isolation, from a narrow slice of data. But AI memory isn’t just about answering correctly in a vacuum—it’s about remembering, connecting, and reasoning across time and information sources.
Evaluating a memory system with EM and F1 is like judging a library by the length of its bookshelves rather than the quality of its cataloging and retrieval. Technically, you’ll get a correct fact, but that doesn't mean the system understands how that fact relates to the broader context.
What Actually Matters for Memory Systems
If you're building or using an AI memory system, these are the metrics that matter most:
-
Consistency
Does the system preserve and apply knowledge accurately over time?
-
Connection Quality
Can it find and link relevant concepts across contexts that aren’t obviously related?
-
Memory Persistence
Does it remember previous inputs and build upon them instead of starting from scratch?
-
Reasoning Depth
Can it handle multi-step questions that require synthesis, not just retrieval?
These are the real benchmarks for intelligence in memory-enabled AI—none of which are adequately captured by legacy QA scoring methods.
Technical Implementation Notes
Evaluation Infrastructure
To support more meaningful and fair comparison between AI memory systems, we expanded our benchmarking toolkit with:
-
Dataset Compatibility
A unified evaluation framework that supports HotPotQA, MuSiQue, and 2WikiMultihop. For this evaluation, we used HotPotQA exclusively.
-
System Benchmarks
Dedicated benchmarking classes for Cognee, Mem0, LightRAG, and Graphiti (with adjustments based on availability). These abstractions handle memory creation, retrieval configuration, and answer generation.
-
Parallelized Runs on Modal
All benchmarks were wrapped in a scalable job system that runs multiple evaluations in parallel on Modal’s serverless infrastructure, enabling faster iteration and consistent resource isolation.
Addressing LLM Evaluation Variance
Since LLM-based evaluations (like DeepEval) can vary meaningfully between runs, we incorporated techniques to reduce noise and improve confidence in the results:
-
Repeated Runs
We ran each evaluation multiple times to account for LLM response variability.
-
Bootstrapped Confidence Intervals
We applied statistical bootstrapping to better understand performance ranges and avoid over-indexing on outliers.
-
Multi-Metric Scoring
By combining EM, F1, DeepEval, and a custom correctness approximation, we ensured no single metric dictated the evaluation narrative.
Looking Ahead: Better Benchmarks for Better AI
The Evaluation We Need
As AI memory systems mature, we need evaluation frameworks that reflect their actual purpose—connecting, reasoning, and evolving across contexts—rather than forcing them into unsuitable evaluation paradigms.
Like our dataset, future benchmarks must evaluate:
- Cross-context reasoning
- Long-range memory coherence
- Inference across documents, modalities, and time
Open Source Contribution
By releasing our new evaluation dataset with DeepEval, we’re contributing to this broader effort. The dataset will be freely available for researchers working on AI memory systems, knowledge graphs, and long-context AI applications.
Evaluation Evolution
Evaluation is always an ongoing process. Our roadmap includes:
- More robust LLM-as-judge protocols
- Hybrid human-machine evaluation frameworks
- Real-world task benchmarking using production data
We're committed to making sure evaluation keeps pace with innovation.
Ready to See AI Memory in Action?
While we build better benchmarks, you can test cross-context memory for yourself today with Cognee Cloud—our hosted platform for building memory‑enabled AI agents.
Or dive right into our our GitHub and read our research paper to explore the technical foundations of how cognee builds and queries knowledge graphs.

Cognee Raises $7.5M Seed to Build Memory for AI Agents

What OpenClaw is and how we give it memory with cognee
