AI Memory Tools - Evaluation
The AI Memory Problem: Why Your LLM Keeps Forgetting Everything
Ever noticed how ChatGPT seems to forget what you were talking about after just a few messages? It’s not just you—it’s a fundamental limitation of all LLM-based applications. While these models are incredibly powerful, they struggle to maintain context across interactions.
The core issue is simple: LLMs don’t have persistent memory. Each interaction with ChatGPT starts from scratch. When you’re dealing with thousands of interactions, that becomes a serious bottleneck.
There are many solutions out there to solve this problem, and we evaluated a few.
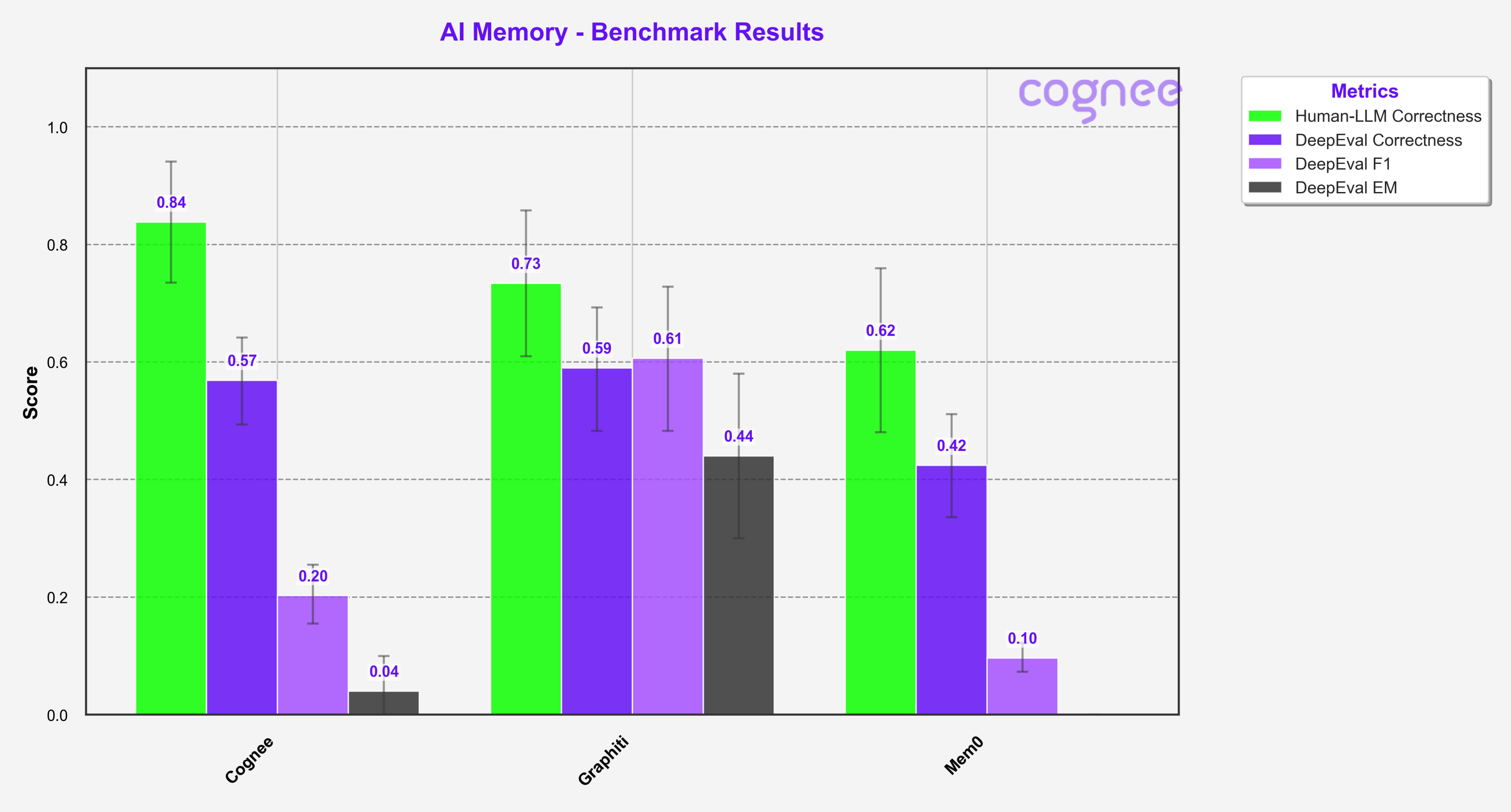
Our evaluation yielded the following results:
Why This Matters (And Why You Should Care)
The performance of your LLM app isn’t just about picking the right model or writing clever prompts. What happens before the prompt—the data pipeline—is just as important.
A well-designed pipeline can elevate simple LLM outputs into rich, context-aware interactions. Take the HotpotQA benchmark, for example. It tests multi-hop reasoning: the ability to pull together information from multiple sources to answer complex questions accurately.
For systems to handle queries like these, they need to:
- Identify relevant information across documents
- Build meaningful relationships between disparate data points
- Deliver structured, coherent context to the LLM
The Current Landscape
We've analyzed the current market for AI memory solutions. Here are the key players we're evaluating:
- Mem0
- Zep/Graphiti
- cognee - check on ourselves
Our Benchmark Approach
We're using the HotPotQA benchmark to evaluate these solutions. Our testing focuses on:
- Multi-document processing capabilities
- Cross-source information integration
- Accuracy in complex reasoning tasks
We take 50 randomly selected questions from the HotPotQA benchmark:
The cognee Way
We used cognee, our AI memory engine, to build a knowledge graph from the paragraphs of the input documents, enabling the identification of intricate relationships within the context that might have otherwise gone undetected.
Finally, a brute-force triplet search is performed on this enriched graph to capture relevant connections or components. This enhanced understanding of the codebase empowers the LLM to make more informed decisions when generating patches.
In the following section, we’ll compare this approach with several other methods used by Mem0 and Graphiti.
The Results
You can verify these results by following the instructions in our GitHub repository.
A few notes on the metrics:
- Human eval means a human manually annotated the results, checked for factual accuracy, and researched the questions involved. We primarily reviewed failing answers, so it's possible that some false positives slipped through.
- F1 scores reflect a balance between precision (how much of what you predicted was correct) and recall (how much of what you should have predicted you actually did).
- EM (Exact Match) scores represent the percentage of predictions that exactly match the ground truth.
- Correctness is a Deepeval metric, where an LLM acts as a judge. Check them out—they’re doing great work toward standardizing LLM evaluations.
Optimizing the steps
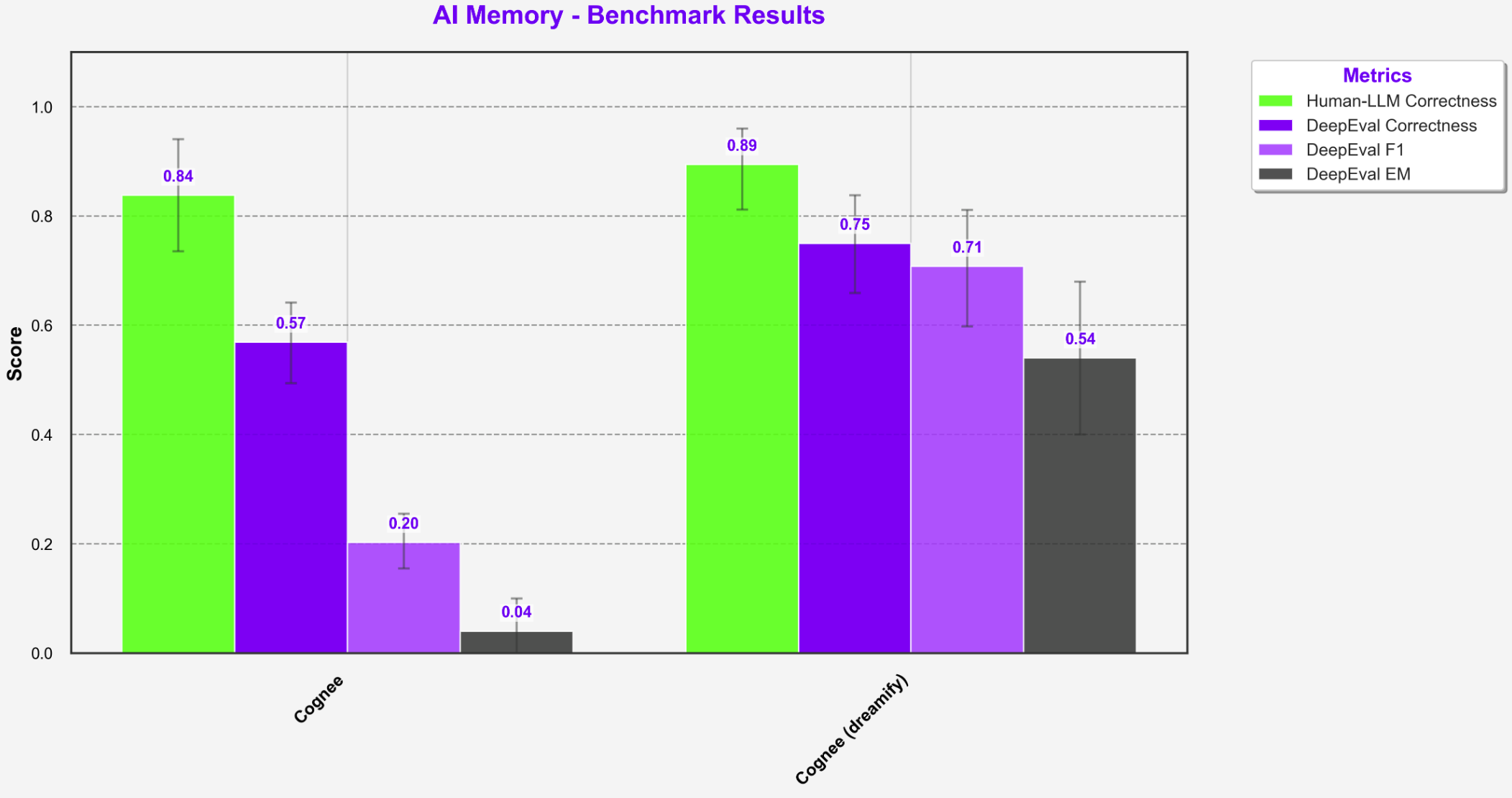
Running cognee with vanilla settings is easy, but making sure the accuracy improves is something we can do using our proprietary tool Dreamify. We imagined that Dreamify would do what your brain does when you sleep, rewire and re-connect the dots, so your cognitive processes can work. As evident in the image bellow, the results are much better after adding our magic sauce into it.
Issues with the approach
- LLM as a judge metrics are not reliable measure and can indicate the overall accuracy
- F1 scores measure character matching and are too granular for use in semantic memory evaluation
- Human as a judge is labor intensive and does not scale- Hotpot is not the hardest metric out there
- Graphiti sent us another set of scores we need to check, that show significant improvement on their end when using _search functionality. So, assume Graphiti numbers will be higher in the next iteration! Great job guys!
What This Means
The results demonstrate that our approach delivers significant improvements in handling complex, multi-step questions. Our system shows clear advantages over existing solutions in the market.
The key insight here is that success isn't just about metrics - it's about the ability to modify the system parameters. We’ve ran cognee out of the box, and when we adjusted the parameters using our internal tool Dreamify and our know-how, we ended up with much more impressive results.
If you need our help to help you tweak the system, let us know.
What's Next?
We're committed to continuous improvement. We're actively developing new features and enhancing our system's capabilities. Join our Discord community to be part of this journey and help shape the future of AI memory systems.


