From Clever Prompts to AI Mastery: The Era of Context Engineering
As capabilities of AI models unstoppably advance, the way we interact with them has to evolve too. It’s no longer enough to throw clever prompts at an LLM and hope for the best. To get consistently reliable and accurate responses, we need to meet these systems at their level—feeding them complete, relevant information and equipping them with the tools to process and act on it. This is where the next big shift in AI development comes in: context engineering.
Unlike “prompt engineering,” which focuses on crafting one-off inputs, context engineering is about designing the entire environment in which an AI model thinks and acts. It isn't just a neat trick—it's the difference between a forgettable chatbot demo and a truly "magical" AI experience, as Philipp Schmid puts it.
In this post, we’ll explore what context engineering is, why it’s critical for modern AI systems, and how it ties directly to AI memory. We’ll also cover practical aspects like structured outputs, personalization, and time awareness—and show why mastering context engineering is becoming an essential skill for anyone serious about building with AI.
What is Context Engineering?
Context engineering has been neatly summarized by Tobi Lutke as “the art of providing all the context for the task to be plausibly solvable by the LLM.” In other words, it boils down to supplying the model with everything it needs—i.e., instructions, data, tools, history—so that it can have enough situational awareness to produce the best possible output. This goes far beyond writing a detailed prompt.
Think of context engineering as curating exactly what an AI sees—just like an operating system abides by a set of efficiency principles to manage what what data it keeps in the RAM, a developer practicing context engineering carefully selects what goes into the model’s limited memory, as described in LangChain’s recent blog post. The key is to provide the right information, at the right time, so the AI can reason effectively.
The Key Components of Context:
- Instructions / System Prompt: The initial guidelines or rules for the model’s behavior (e.g. a system message defining the AI’s role and style). This can include examples or policies that persist throughout the session.
- User Prompt: The immediate query or task request from the user. (This is the part people traditionally focus on in prompt engineering, but it’s only one piece of context.)
- State / Conversation History (Short-Term Memory): The running log of dialogue so far—recent user messages and the AI’s responses that led to the current point. This short-term memory provides continuity and prevents repetition.
- Long-Term Memory: Persistent knowledge that the AI has “learned” or stored across sessions. This might include facts the user told the AI to remember, summaries of past interactions, or user preferences gathered over time. Long-term memory enables personalization—the AI can recall a user’s favorite style or previously given information even in a new session.
- Retrieved Information (External Knowledge via RAG): Any relevant data fetched from outside sources at query time. This is where Retrieval-Augmented Generation (RAG) comes in—for example, pulling in facts from a database or documents to supplement the AI’s knowledge. It ensures the model has up-to-date or detailed info beyond its built-in training data.
- Available Tools and Actions: Definitions of tools or APIs the AI can use (in agent frameworks). For instance, an agent might have a tool for web search or booking a calendar; the descriptions of these capabilities are part of the context so the AI knows they exist. Tool outputs themselves also become context for subsequent steps.
- Structured Output Requirements: Instructions or examples defining the format of the AI’s response (e.g. “You should output a JSON object with fields X, Y, Z”). By including expected output schemas in context, we guide the model to produce well-structured results.
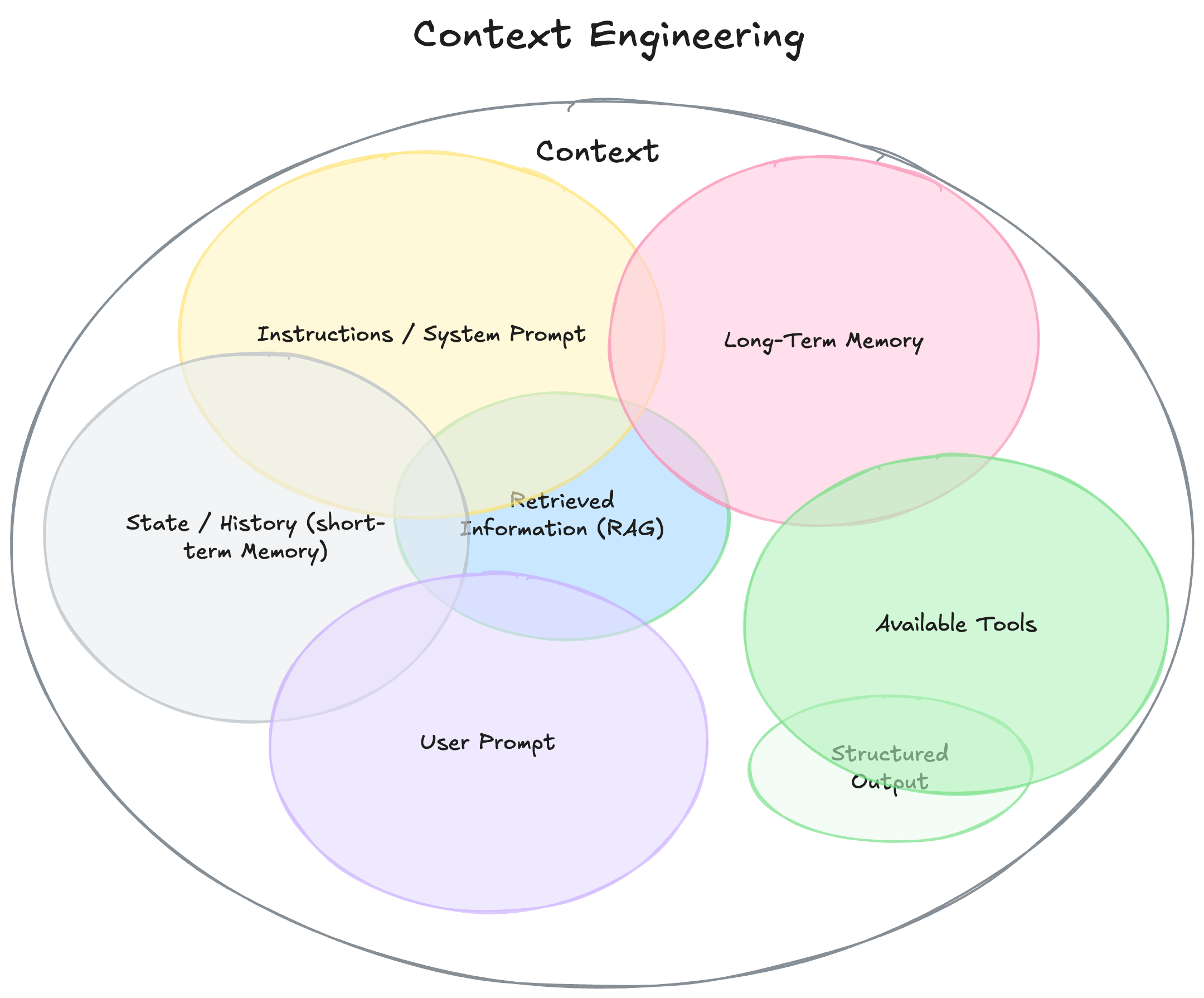
Source: https://www.philschmid.de/context-engineering
As Dex Horthy noted in his 12-Factor Agents manifesto, in an agent setting the input is essentially: “Here’s what happened so far—what’s next?” In this perspective, everything the model consumes becomes part of context engineering.
Because LLMs are stateless—they only know what we feed into the prompt at each step—providing the right context is absolutely critical for generating accurate, relevant outputs. The bottom line is—context engineering elevates AI memory from a simple buffer into a carefully designed and dynamic system.
Why Prompt Engineering Doesn’t Quite Cut It
Previously, AI developers relied on prompt engineering—carefully crafting a single input to coax good behavior from the model. That might involve detailed, step-by-step instructions which may include an example or few (few-shot learning). The emerging concept of context engineering implies a much broader, more systematic process.
According to Simon Willison, the shift in terminology arose because ‘prompt engineering’ was often misunderstood as ‘just typing clever inputs,’ whereas context engineering conveys the true complexity of advanced querying. “Most people’s inferred definition [of prompt engineering] is that it’s a pretentious term for typing things into a chatbot,” he **notes. By contrast, context engineering immediately implies carefully curating everything in the context window—a meaning much closer to the intended practice. Thus, the term is likely to stick as the preferred denomination for this holistic system-level skill.
Instead of one clever prompt, engineers are now building entire context pipelines, which typically involve multiple steps of processing before the final LLM call—for example, retrieving documents, summarizing long texts, fetching user preferences, adding metadata like source citations or timestamps, enriching the context by connecting it with other relevant information, and only then asking the model for an answer. Prompt engineering is just a small section of this complex discipline.
Solving the AI Memory Problem
As AI systems take on increasingly complex, long-running tasks (especially with autonomous agents or multi-step workflows), managing context becomes the biggest challenge. When you build an AI agent, you spend most of your time figuring out what information to give the model (and what to withhold), how to effectively summarize or recall past events, and how to keep the context window from blowing up. AI memory is at the heart of this challenge.
When we say AI memory, we don’t just mean simple chat logs or conversation history. AI memory encompasses all information from past interactions that could prove relevant now or later—things like user profiles, stored knowledge, the state of ongoing tasks, and previous results from external tools.
For example, a customer support chatbot might have long-term memory of the user’s account details and past support tickets, so that it can avoid asking redundant questions and offer more meaningful and to-the-point assistance. Context engineering handles this by storing the data in a way that it can be used well by LLMs, pulling the right records from a database and including a summary in the system prompt. So it’s essentially the practice of managing AI memory—deciding what information should be injected into the prompt context at any given step.
Platforms like cognee provide an external memory layer that stores information (and the relationships between datapoints) durably, enabling the AI to recall that knowledge in future queries. This effectively gives the model a memory, leading to far more context-rich and personalized responses.
Context engineering matters greatly for several key reasons:
- Reliability: An AI provided with the right context delivers consistent and accurate responses. Including critical details, user constraints, or preferences reduces the chance of errors and hallucinations.
- Performance: Research has shown that giving a GPT model cognitive tools or context significantly boosts its performance on complex tasks. For example, providing intermediate calculation results or relevant facts helps the model carry out multi-step reasoning more effectively than when trying to do it all in one prompt.
- Personalization: User-specific context, such as previous questions, names, preferred language tone, known topics of interest, transforms generic responses into personalized interactions, greatly enhancing user experience.
- Task Success: For agentic systems, task success often hinges on available context. In multi-step operations, it’s the “secret sauce” that makes an agent robust and “magical” by giving it clarity on tool use and the next action steps.
- Preventing Errors and Drift: Techniques like pruning irrelevant history, resolving conflicting information, and highlighting important details keep AI agents focused and effective during lengthy sessions.
Ultimately, context engineering is about proactively managing AI memory—ensuring the model is always supplied with precisely the right information. This strategic management shifts AI interactions from treating models as opaque "black boxes" to components actively supported by a well-managed memory state.
Context Engineering in Practice: Key Techniques and Examples
So, what does context engineering look like in practice? It often means incorporating a variety of techniques to supply and manage context. Below are some key aspects and examples of context engineering.
Dynamic Memory
In complex reasoning or coding tasks, agents often use dynamic "scratchpad" memory—storing intermediate steps or notes outside the primary prompt—to handle complex tasks without overloading their context window. LangChain describes this as external context writing: selectively injecting essential notes into the context as needed.
For example, Anthropic’s research assistant writes its plan to a memory after each turn so it won’t be lost even if the context window refreshes. The context engineer decides what persists (important conclusions, the high-level plan) and what can be pruned away.
Context Selection and Retrieval
In many applications, there’s far more potential context (fragmented documents, knowledge base entries) than can fit in the model’s window. Retrieval-Augmented Generation (RAG) is central to context engineering, as it allows models to dynamically retrieve and integrate precise, relevant information into prompts on the fly.
Context engineering ensures that retrievals are meaningful and relevant. It addresses the question “what info should be pulled into the prompt to help answer this query?” and uses various search methods to fetch that context.
Knowledge Graphs and GraphRAG
More advanced contexts rely on structured knowledge graphs that enhance complex, multi-step reasoning. Graph-based RAG retrieves not just text snippets but interconnected entities, forming a meaningful subgraph of related, even disparate, facts.
For example, answering "How is person X related to concept Y?" might retrieve a chain of relationships from a knowledge graph to give to the model. As we move from prompts to full context systems, we upgrade our retrieval too—from simple similar-text lookup to relationship-aware, graph-based retrieval. This yields a more structured, interconnected context, which reduces ambiguity and allows the AI to reason over connected pieces of information.
Knowledge graphs are especially promising for domains where facts are linked (e.g. scientific research, enterprise data) since they provide the model with a map of how things relate, not just isolated snippets.
Structured Output Templates
Defining structured output formats (like JSON schemas or Markdown tables) ensures AI responses integrate seamlessly with other systems or APIs. Providing clear format guidelines or example outputs helps maintain consistent, predictable results.
Modern agent frameworks often allow defining an output schema for the model to follow. Elvis Saravia noted that this is “one underrated aspect of context engineering” – by giving format instructions and even example JSON templates, you can greatly improve the consistency of the agent’s outputs.
For instance, if your agent needs to output a list of tasks with fields like id, query, time_period, etc., you might include in context a dummy JSON showing that format. In effect, you treat the format as additional context the model must adhere to.
Time Awareness
Many tasks require accurate temporal context—something models trained without live data inherently lack. Injecting current date/time information directly into prompts enables accurate temporal reasoning. A simple context inclusion, such as “The current date and time are: 2025-07-15 09:40:00 (UTC+2)” provides models with necessary temporal reference points for accurate responses.
User Personalization and Profiles
Personalizing interactions requires maintaining user profiles—carrying names, preferences, past interactions, or specific contextual cues across sessions. For instance, a writing assistant can store a user’s style preferences, injecting relevant context (“The user prefers concise answers") to enhance the AI’s understanding and responsiveness.
Effective context engineering carefully manages this information and yields responses that feel contextually aware of who the system is talking to. It’s worth noting that privacy and data freshness are also considerations here: context engineering must involve user permissions and other data privacy constraints.
Error Handling and State Management
Errors such as failed API calls or unexpected tool responses inevitably occur in complex agent systems. Effective context engineering incorporates these errors directly into the AI’s context, enabling the model to reason about the issues and recover from them.
As an example, you might add a line in the context like “(Note: the previous attempt to fetch data X failed due to Y error)”. This informs the model of what happened so it can adjust its plan (maybe try a different approach or ask the user for input).
Once the error is resolved, you might remove or mark that context so it doesn’t clutter future steps. This dynamic updating of context is akin to how robust software handles exceptions—but it exemplifies that context engineering is an ongoing process during an agent’s lifecycle, not a one-time prompt.
Context Window Optimization
With finite context windows, part of context engineering is figuring out how to fit as much useful information as possible into the available tokens. This can involve various techniques like summarization, compression, encoding data in more compact formats, and selective data retention.
Advanced implementations use algorithms to decide which pieces of context to keep and which to drop at each step. This ensures the most relevant bits are always in memory for the AI, much like how humans focus on key facts when solving a problem.
As we can see, context engineering spans a wide range of techniques. It’s a holistic practice that requires understanding both the technical tools (like vector databases, knowledge graphs, session stores) and the problem domain (what information is actually critical to solving the task at hand).
Mastering Context Engineering for Modern AI Systems
As we've seen, context engineering spans a wide variety of techniques, tools, and processes. But its real value lies in its holistic nature: it demands both technical expertise—like familiarity with vector databases, session management, and knowledge graphs—as well as a deep understanding of the domain itself (i.e., knowing exactly what information matters at each step of the task). With modern AI architectures rapidly shifting towards autonomous agents and complex tool-using workflows, context engineering has moved to the very center of how we build AI today.
Every action an agent takes—using external tools, querying databases, or retrieving documents—generates new context that expands its working memory. Without a methodical, scalable approach, this context can quickly become unwieldy, noisy, and, ultimately, counterproductive. Effective context engineering ensures agents don't drown in unnecessary detail but always retain immediate access to the critical insights needed to complete their tasks effectively.
This is exactly where platforms like cognee become vital. By combining structured knowledge graphs with high-speed vector searches, cognee can enable AI agents to intelligently store, manage, and retrieve vast amounts of context without overwhelming their memory limits.
Rather than naively stuffing every intermediate result back into a flat prompt—which risks context overload and confusion—cognee persistently stores each new data point, along with its semantic relationships with other entities, into a comprehensive knowledge graph. Each entry is also vectorized for instant retrieval, meaning agents only receive precisely the subgraph of knowledge relevant at that exact moment.
This hybrid “graph + vector” architecture empowers agents with a lean yet comprehensive context—ensuring they always have just enough information to reason effectively without hitting token limits or losing accuracy. With this kind of structured scaffolding in place, developers can confidently layer sophisticated features on top, such as multi-agent coordination, dynamic planning, and deeper personalization.
Basically, using platforms like cognee for context engineering has the potential to move AI development beyond prompting and fragile manual memory management. Instead, CE can become a robust engineering discipline—structured, auditable, and reliable by design. Its result? AI systems that feel genuinely intelligent, maintaining rich, adaptive memories capable of driving personalized interactions, precise outputs, and self-improving decision-making.
Context is King: Artificial → Genuine Intelligence
The shift from prompt engineering to context engineering marks a significant milestone on the path of building powerful and reliable AI systems. We've moved away from treating prompts as magic incantations or solely relying on fine-tuning models; instead, we now recognize the importance of carefully orchestrating context and memory—treating an AI’s context window as valuable real estate and thoughtfully populating it with exactly the right synergy of information, enabling models to reason clearly and effectively.
For developers and organizations, investing in context engineering translates into building smarter systems that remember context over time, personalize interactions, tackle more complex tasks, and operate more efficiently. Done right, context engineering transforms AI from a one-off oracle into an interactive problem solver, capable of dynamically adapting to new information and carrying out goals through sustained interactions. In many ways, context engineering is about imbuing AI systems with genuine intelligence.
Looking ahead, as context windows grow larger and memory management systems become even more sophisticated, the potential and importance of context engineering will only grow. Similar to established software architecture pattern, standardized memory architectures focusing on context management, knowledge intake, and response structuring will emerge. It's clear that context engineering—and AI memory more broadly—is at the forefront of modern AI development. Those who master this discipline will unlock what will feel like deep awareness in their AI systems.
If you're curious to see what we’ve discussed here in action, check out the cognee repo. Many teams are already using cognee to organize their data and streamline their agents’ prompts, while surfacing meaningful relational insights on demand. You can browse code samples, integrate your documents, and begin experimenting with cognee’s powerful AI memory layer in just minutes. In case you need inspiration or you want to discuss topics around context engineering and AI memory, r/AIMemory is the place to be.
FAQs
1. How do I get started with context engineering in practice?
To start context engineering effectively, first identify what context your model might be lacking for more reliable and accurate retrievals. Then, set up a workflow to systematically feed it this information. Frameworks like cognee or LangChain can help you build pipelines quickly and experiment with context management techniques.
2. What common mistakes should I avoid in context engineering?
Common pitfalls include overloading the model with unnecessary or repetitive information, neglecting structured formatting (causing inconsistent outputs), and failing to manage context window limitations effectively. Also, ensure your context retrieval is precise; irrelevant context can degrade model performance.
3. How does context engineering affect the cost of running LLM-based applications?
Good context engineering can significantly reduce operational costs by optimizing the context size—fewer tokens mean cheaper API calls. Techniques like summarization, dynamic retrieval, and strategic memory usage help minimize context bloat and improve both cost efficiency and response quality.
4. What are RAG and GraphRAG, and why are they important in context engineering?
Retrieval-Augmented Generation (RAG) involves retrieving relevant information from external databases and injecting it into the model’s context at query time. GraphRAG retrieves structured knowledge from knowledge graphs, with a focus on relationships between data points extracted from the ingested information. These methods enable the AI to reason better by providing more detailed and interconnected information than simple text-based retrieval.
5. What role do vector databases and knowledge graphs play in context engineering?
Vector databases enable fast retrieval of semantically similar content, which is essential for RAG-based context engineering. Knowledge graphs provide structured data relationships (GraphRAG), facilitating deeper reasoning. Both play critical roles in assembling relevant, precise, and relationship-rich context for AI models.
6. Are there privacy concerns in context engineering?
Yes, managing user-specific data as context requires careful handling of privacy and compliance. Always ensure that user consent, data minimization practices, and proper anonymization or encryption techniques are in place when storing and retrieving personal context data.
7. Can context engineering improve the explainability of AI decisions?
Yes. By explicitly controlling and providing context, developers gain greater visibility into the information influencing the AI’s responses, making it easier to trace and explain model outputs. Structured context also helps audit the reasoning paths the model takes.


