Graph Databases Explained: A Better Way to Represent Connections
Graph databases let us navigate data as effortlessly as exploring ideas on a well-organized digital whiteboard. On this board, each sticky note represents an entity—a person, place, or object—while every arrow shows how those entities connect. Rather than squeezing this network of relationships into rigid tables or scattering it across different documents, graph databases place them front and center, allowing applications to move seamlessly through linked entities (e.g. ""Andy Jassy" → Amazon" → "Seattle"") in milliseconds.
This powerful structure makes graph DBs ideal for use cases where understanding relationships is just as important as the data itself—such as for powering social media feeds, detecting suspicious digital activity, or providing highly personalized recommendations. In this post, we'll unpack how graph databases work, explore why platforms like Neo4j became so popular, and introduce rising stars such as Kùzu and FalkorDB.
Buckle up—once you start thinking in graphs, you might never see your data the same way again!
What Exactly Is a Graph Database?
A graph database is a type of database specifically designed to store and query data as graphs. But what exactly does that mean?
In a graph database, data is represented by:
- Nodes: individual entities (people, products, cities, etc.).
- Edges: relationships or connections between those entities.
- Properties: attributes attached to both nodes and edges to form key–value pairs (e.g. names, locations, or types of relationships).
In essence, a graph database emphasizes relationships between data items as first-class data, unlike relational databases which force relationships into foreign keys and join tables.
Here's a simple example: Imagine a simple graph database with three nodes—"Andy Jassy," "Amazon," and "Seattle." Andy Jassy is connected directly to Amazon via a "works_at" relationship, and Amazon is connected to Seattle through an "is_in" relationship. This mini-network clearly tells us: "Andy Jassy works at Amazon, which is located in Seattle."
If we would draw out this structure, "Andy Jassy," "Amazon," and "Seattle" can be represented as circles, with arrows "works_at" and "is_in" indicating their connections. This diagram essentially represents how ingested data is stored in a graph database.
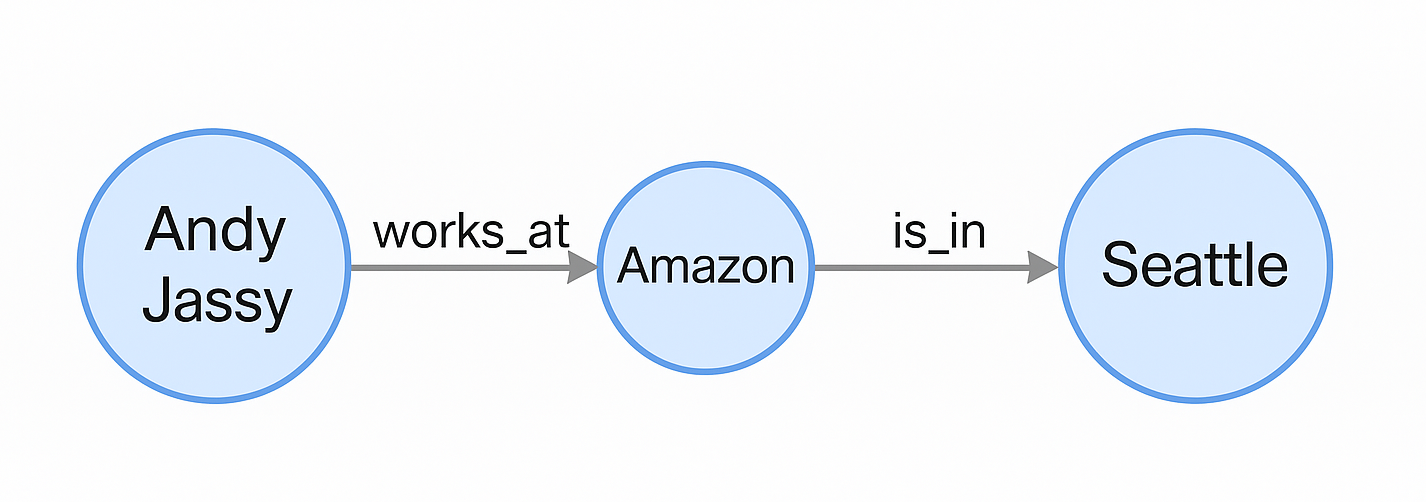
Because this structure focuses explicitly on relationships, graph databases are sometimes referred to as network databases or knowledge graphs, especially when used for representing complex knowledge domains. One well-known example is Google’s Knowledge Graph, which stores facts about entities like people, places, and objects to answer user queries efficiently.
How Does This Differ from Traditional Databases?
In a relational database (like SQL), "Andy Jassy" might reside in a "People" table, "Amazon" in a separate "Companies" table, with a different table or foreign key linking them. This separation means the database must perform JOIN operations at query time to resolve connections, which can be slower and more complex.
In contrast, a graph database directly stores these relationships alongside the data itself. Andy Jassy explicitly holds a "works_at" relationship to Amazon (with additional details, such as his role as CEO). Queries like "In which city does Andy Jassy work?" are resolved rapidly and intuitively because the database simply follows pre-existing connections without complex joins.
Graph Databases vs Relational and Document Databases
The unique advantages of graph databases becomes clearer when comparing them to other database types, specifically relational and document stores.
Relational Databases (SQL)
Relational databases organize data into structured tables (rows and columns) with strict schemas. They perform exceptionally well for transactional workloads, set-based queries, and large-scale aggregations.
However, relationships between data points are not stored directly. Instead, they are implied through foreign keys or managed via join tables. As the number of relationships—or the depth of those connections—increases, querying across them becomes increasingly complex, cumbersome, and computationally expensive.
For example, answering a question like “Who are Alice’s friends-of-friends?” requires multiple JOIN operations, each one adding to the query’s complexity and performance cost.
Document Databases (NoSQL)
Document databases, such as MongoDB, store data in flexible, JSON-like documents. They're ideal for nested, hierarchical data (one-to-many contained relationships like product catalogs or user profiles) and allow rapid schema evolution. However, they're not optimized for many-to-many relationships across multiple documents.
While you can store references (such as IDs) within documents, it’s up to the application to resolve those links, and this process often requires additional queries or application-side logic. For use cases with frequent cross-referencing—like social network friendships or product recommendations—this pure document store can quickly become unwieldy.
Graph Databases (Property Graphs / RDF)
Graph databases explicitly store data relationships as first-class citizens. Relationships are directly embedded with the data, enabling efficient multi-hop traversals. Queries involving complex (many-to-many) relationships—like finding indirect connections between entities—are exceptionally fast and intuitive.
Unlike relational or document databases, graph databases effortlessly navigate intricate networks, making them perfect for highly connected data scenarios.
To summarize:
- Relational DBs are great for structured data and bulk operations but struggle with complex relationships due to heavy JOINs.
- Document DBs offer flexible schemas and nested data, but cross-document links require extra handling.
- Graph DBs excel at navigating highly connected data, with relationships stored directly for fast, multi-hop queries.
| Feature / Aspect | Relational (DBMS – SQL) | Document (DBMS – NoSQL) | Graph (DBMS – Property / RDF) |
|---|---|---|---|
| Data model | Tables (rows × columns) | JSON/BSON-like documents | Nodes & edges with properties |
| Schema | Rigid, predefined (DDL) | Flexible / schema-optional | Flexible / schema-optional |
| How relationships are stored | Foreign-key references in separate columns or join tables | References (IDs) inside documents; not natively linked | Relationships are first-class edges stored alongside nodes |
| Typical query language | SQL (SELECT…JOIN…) | Query DSLs / API (e.g., MongoDB find, aggregation) | Cypher, Gremlin, SPARQL, GQL (pattern-matching / traversals) |
| Relationship traversal cost | Requires JOINs; cost grows with each hop (multi-join) | Needs extra look-ups or app-side code; many-to-many is heavy | Pointer-like hops; multi-hop traversals are constant-time per hop |
| Performance sweet spot | Large set operations, aggregations, strict ACID transactions | Hierarchical / nested data, rapid schema evolution, denormalized reads | Highly connected data, deep or ad-hoc relationship queries, graph analytics |
| Common use cases | Financial ledgers, ERP, OLTP workloads | CMS, product catalogs, user profiles, logging | Social networks, knowledge graphs, fraud rings, recommendation engines |
| Scaling approach | Vertical scaling; sharding possible but complex joins suffer | Horizontal scaling via sharding/replica sets | Varies: single-node native graphs, distributed graph clusters, or embedded libs |
| Key limitation | Joins get slow/complex with deep relationships | Many-to-many cross-document queries are costly | Not ideal for large set-based joins or heavy aggregations that ignore edges |
Why Use a Graph Database?
The main reason to use a graph database is simple: relationships matter.
Many real-world datasets are inherently connected—think of people and their social networks, products and purchase histories, or entities in a supply chain. In these cases, insight comes not just from the data itself, but from how the data is linked. Graph DBs are designed to traverse those connections, fast.
Here’s why they shine:
- Intuitive Data Modelling: Graphs reflect how we naturally understand networks. Rather than cramming complex structures—for example, organizational charts or transit systems—into rigid tables, representing them as nodes and relationships feels more logical and relatable. It’s far more intuitive to model “who reports to whom” or “which routes connect which cities” as a graph than as a series of fragmented spreadsheets. This approach makes the data easier to design, explore, and explain—especially for non-technical stakeholders.
- Powerful Relationship Querying: Because relationships are stored directly in the database, graph queries can explore multi-hop patterns (like “find all doctors who have treated patients that have also seen specialist X” or “find fraud rings of accounts connected by shared phone numbers and addresses”) in a way that’s very hard to do with other storage solutions. To paraphrase Selen Parlar’s observation, graph databases hold relationships as a priority, so querying them is fast because they’re pre-materialized in the data store.
- Flexibility and Schema Evolution: Most graph DBMSs are schema-optional or schema-flexible. You can add new entity types and relationships without the pain of full migrations. This is useful for evolving domains or integrating diverse data sources (common in building or Enhancing Knowledge Graphs with Ontology Integration).
- Uncovering Hidden Patterns: Graphs can help reveal hidden patterns or indirect links between data points. For example, by traversing connections, you might find that two seemingly unrelated customers are actually connected through a series of intermediary accounts or that a set of research papers share a common co-author via chains of collaborations. Graph analytics algorithms (like centrality or community detection) can run on graph databases to further take advantage of these connections.
In short, when your use case revolves around how things are connected—not just what they are—graph databases provide a natural, performant, and insightful solution. If questions about “hops” or degrees of separation or pattern matching in relationships are frequent in your application, that’s a strong signal a graph database could be beneficial.
Common Use Cases for Graph Databases
Graph databases are gaining traction across industries as more organizations realize the value of data connectedness. Below are some of the currently most popular applications for graph DBs.
Social Networks
Social media platforms (Facebook, LinkedIn etc.) were early adopters of graph DB technology. Each user is a node, with relationships like FOLLOWS, FRIENDS_WITH, or LIKES connecting them.
A graph database makes it easy to find things like friends-of-friends, influencer networks, or community clusters. For example, LinkedIn can show your 1st, 2nd, and 3rd degree connections instantly because it organizes its hundreds of millions of users in a graph. Traversing those connections by levels is exactly what graph queries are optimized for.
Recommendation Engines
E-commerce and streaming services use graphs to recommend products or content based on shared interests or behaviors. Nodes might be customers, products, or movies, with edges representing PURCHASED, VIEWED, or LIKED. By traversing the graph, the system can find users with similar activity and provide personalized suggestions like “people who bought/saw/liked X also bought/saw/liked Y.”
A graph database can store this interaction web and answer “what else is connected to this item?” very efficiently. Amazon’s famous product recommendations and many other “you may also like…” features on websites rely on graph relationships.
Fraud Detection
Financial institutions and insurance companies use graph databases to detect fraud rings and instances of suspicious activity. If you connect entities like bank accounts, credit cards, IP addresses, and email addresses, patterns such as one email linked to multiple people or one device used across many accounts can indicate fraud.
Graph queries can uncover indirect links (fraudsters often use chains of accounts). Because graphs can be queried practically in real-time, they can help the system flag fraudulent transactions by spotting a known bad pattern of connections before the transaction completes.
Knowledge Graphs and Data Integration
Enterprises often unify siloed data into knowledge graphs—linking customers, support tickets, internal docs, and more (for instance, a biomedical knowledge graph linking diseases to symptoms to medical histories to treatments).
Graph databases are used for this knowledge management because they provide a flexible schema and can capture complex metadata relationships. An example knowledge graph is the one used in Wikipedia’s backend or Google’s Knowledge Graph, which helps answer factual queries directly.
IT & Network Operations
Graphs naturally model networks in telecommunications or IT. Routers, servers, applications, and their dependencies can be represented as nodes, with edges capturing relationships like CONNECTS_TO or DEPENDS_ON.
This structure enables efficient impact analysis—such as identifying which applications would be affected if a specific server fails—and supports smarter route planning and optimization. In transportation and logistics, graph databases can model complex route networks and calculate shortest paths, making delivery scheduling and supply chain management more efficient.
Identity and Access Management
Access control in an organisation can be effectively modelled as a graph—where users, roles, permissions, and resources are nodes, and relationships like HAS_ROLE or CAN_ACCESS are edges. Graph queries make it easy to answer questions like “Which systems does a departing employee have access to?” or “Which users hold a specific combination of privileges?” These queries are far more straightforward and performant as graph traversals than trying to construct complex SQL joins across multiple user, role, and permission tables.
Across all the above (and many other) examples, the common thread is connectedness. If your data lives in a web of relationships, a graph database helps you make sense of it quickly and meaningfully.
How Do Graph Queries Work?
Unlike SQL, which is based on table joins, graph databases use pattern matching or graph traversal to query relationships directly.
Pattern-Matching
Languages like Cypher (used by Neo4j) allow you to describe patterns of nodes and relationships to find in the graph. In it, you might write a query like:
This query finds all persons who live in the same city as Alice (the pattern describes a Person connected to a City which connects back to another Person). The database starts at the “Alice” node and traverses her LIVES_IN edge to the city she lives in, then find other people (nodes) who also LIVES_IN that city.
The result might be a list of Alice’s city-mates, which could be considered “friends of friends” if you also had a friend relationship in the mix. Cypher is declarative like SQL, meaning you describe what pattern you want, and the engine figures out how to get it.
Traversal APIs
An alternative is a procedural (step-by-step) traversal approach, exemplified by Gremlin (part of Apache TinkerPop, used by databases like JanusGraph, Amazon Neptune, etc.).
Querying Gremlin is like giving precise walking instructions: “start at Alice, follow the LIVES_IN edge to City, from that City go out the LIVES_IN edge to other Person nodes, collect those persons’ names.” In Gremlin, this might be written as:
Both Cypher and Gremlin can accomplish the same result—just through different paradigms. Some developers prefer Cypher’s SQL-like readability, while others like Gremlin’s programmatic control.
There are also languages like SPARQL (for RDF graph databases, often used in semantic web contexts), which are a bit like SQL for triple-patterns, and standards emerging (like GQL, a future ISO standard graph query language). However, for most property graph databases, Cypher and Gremlin are still dominant.
What Makes Graph Queries Fast?
Under the hood, graph databases optimize for traversal speed by storing direct references between nodes. This technique—known as index-free adjacency—means each node holds pointers to its neighbors, allowing constant-time “hops.”
For example, when you ask “Who are Alice’s friends of friends?”, the database doesn’t need to search an index. It simply follows connections—pointer to pointer—without join overhead.
By contrast, a relational database might scan join tables and use B-trees or hash indexes to reconstruct connections—this process is both slower and more resource-intensive.
That said, graph queries aren’t magical; they’re simply well-optimized for certain patterns. While they excel at relationship-driven queries, they may underperform on large-scale set-based operations that don’t rely on connections.
For example, querying a graph database for all nodes with a certain property—without following any edges—could require scanning many nodes unless the database maintains a dedicated index.
In practice, many graph DBMSs do offer indexing features for node lookups based on properties, helping you quickly locate a starting point for traversal. But if your workload primarily involves bulk aggregations, filtering by attribute, or operations that ignore relationships altogether, a relational database may still deliver better performance.
The key is choosing the right tool for the job—and in highly connected domains, graph queries can offer unmatched speed and flexibility.
Choosing the Right Graph Database: Popular Platforms and Tools
There are many graph database systems out there, both open-source and closed. Here are some examples, each with different use cases and priorities:
- Neo4j: Arguably the most popular graph database, Neo4j is often the first one people try. It’s been around since 2007 and is a mature, robust graph DBMS with full ACID transactions.
Neo4j uses the property graph model (nodes and relationships with properties) and the Cypher query language. It’s known for being developer-friendly, has a large community, and tons of integrations (you can use Neo4j with Python, Java, JavaScript, etc.—it has a binary protocol called Bolt and drivers for many languages). Neo4j is available in a free community edition and paid enterprise editions, and it also offers a cloud service called Neo4j Aura.
This system’s performance is strong for OLTP-sized graphs (up to billions of relationships on a single server) and it also has a graph data science library for algorithms. Many knowledge graph projects and recommendation systems have been built on Neo4j. If you see Cypher code examples in tutorials, they’re likely using Neo4j.
- FalkorDB: A newer, open-source graph database that’s optimized for AI/ML knowledge graphs and retrieval use-cases. It’s unique because it’s built on top of Redis (using the Redis Modules API) and it leverages a sparse matrix representation internally (similar to RedisGraph’s approach).
FalkorDB supports the Cypher query language (actually OpenCypher, so it’s syntactically familiar to Neo4j users). It markets itself for GraphRAG (Graph Retrieval Augmented Generation), meaning it’s aiming to serve as a knowledge graph backbone for LLMs applications in real-time.
In terms of performance, FalkorDB is optimized for low-latency querying via linear algebra for query execution, so it aims to answer graph queries extremely fast. It’s a good example of how graph databases are evolving to meet new demands in the AI era.
- Kùzu: An embeddable, open-source graph database that recently came out of academia (the team includes database researchers). It’s been nicknamed the “DuckDB for graphs,” meaning you can embed it in your application (like a library) rather than running it as a separate server process.
Kùzu is designed for query speed and scalability on very large graphs. It’s fully ACID and supports Cypher as the query language. Under the hood, it uses a columnar storage for adjacency lists and a lot of vectorized query processing techniques. It even includes features like full-text search and vector similarity search built-in, which is quite cutting-edge.
Kùzu shines for analytical graph workloads (think of running complex queries that touch a large portion of the graph, e.g., computing metrics, doing graph-wide aggregations). Since it’s embeddable, you could use it within a Python or C++ application without a network hop, which is great for certain use cases like desktop analytics tools or edge devices. It’s MIT-licensed and still in active development.
- NetworkX: While not a database itself, NetworkX is an extremely popular Python library for creating, manipulating, and studying graphs (networks). Developers and data scientists use NetworkX for prototyping graph algorithms, analyzing network properties, and small-scale graph problems.
It’s pure Python and not optimized for performance on very large graphs (if you tried to load 100 million nodes into NetworkX, it would not be happy). But for small to medium graphs, or when you need to quickly write your own graph traversal or run classic algorithms like shortest path, NetworkX is extremely handy. Think of it as an in-memory graph toolkit. It does not have a query language; instead, you work with it via Python code.
- Amazon Neptune: Neptune is Amazon Web Services’ fully managed cloud graph database service. It’s a purpose-built graph engine that supports both the property graph model (with Gremlin as the query language) and the RDF model (with SPARQL).
This duality means you can use Neptune for SQL-like semantic graphs (RDF triples like “Alice – IsFriendOf – Bob”) or property graphs with vertices and edges. Neptune is designed to scale and handle billions of relationships, with high availability across multiple AZs (availability zones) and read replicas for scaling reads.
Because it’s managed, AWS handles the patching, backup, clustering, etc., so developers can just consume it via endpoints. It’s often used when companies are already on AWS and need a graph solution that integrates with their cloud infrastructure.
Common Neptune use cases include knowledge graphs, fraud graph analytics, and social applications – essentially the same as any graph DB, but chosen by those who prefer a managed service. Neptune’s performance is tuned for low-latency graph queries at scale, and it has features like Neptune ML, which integrates with graph machine learning.
- RedisGraph: This is a module for the Redis in-memory database; as such, it inherits Redis’s lightning-fast, in-memory graph processing.
RedisGraph specifically uses a sparse adjacency matrix representation and the GraphBLAS library for high-performance graph operations. It supports Cypher queries (with some limitations, as it doesn’t have the full breadth of Cypher that Neo4j has, but it covers a lot).
Because Redis is often used for caching and real-time apps, RedisGraph finds use in scenarios where you need ultra-fast graph operations in a smaller dataset that can fit in memory. For instance, if you want to do real-time social feed updates or matchmaking in a game (where players are nodes and you want to find suitable opponents based on connections), RedisGraph could be a fit.
It’s worth noting that, as of recent updates, RedisGraph’s development has slowed (Redis Inc. focuses on other modules too), but it’s a fascinating approach to graph—treating the problem as one of linear algebra. An advantage is if you already have a Redis instance, adding the graph module can be straightforward, and you can even combine graph queries with other Redis data structures in one application.
Other notable mentions include TigerGraph (a high-performance parallel graph database often used for enterprise analytics), Dgraph (distributed graph database with native GraphQL support), ArangoDB (another multi-model database that supports graphs), JanusGraph (a distributed, scalable graph database), OrientDB (an interesting multi-model database), and Apache Jena or Virtuoso (for semantic web/RDF graphs). The landscape is rich, and the best choice depends on factors like data size, query complexity, real-time requirements, and existing tech stack.
Relationships Are the Heart of Your Data
Graph databases offer a compelling way to work with connected data by making relationships a core part of the model.
For non-technical folks, the idea of a database that behaves like a network of data (much like a mind-map or web of connections) can be easier to grasp when the domain naturally involves links—such as people to their friends, customers to products, or web pages linking to other web pages.
This intuitive nature is why product managers and system architects are increasingly turning to graph databases when designing solutions for social networks, recommendation systems, fraud detection, knowledge graphs, and more.
The capability to answer complex relationship-driven questions—like "Who are the key influencers linking groups of users?" or "What supply chain links could be impacted by a delay in part X?"—in milliseconds can significantly transform business insights.
From a technical perspective, graph databases achieve this through advanced storage and retrieval methods that bypass the join limitations typical of relational databases. Techniques such as index-free adjacency, adjacency matrices, and specialized query engines help graph databases rapidly traverse relationships and deliver high performance on suitable queries.
However, adopting a graph database isn't a silver bullet for every data challenge. If your data isn't highly interconnected or your queries rarely involve relationship traversals, graph databases might underperform.
cognee: The Next Step Towards Smarter Connections
That's precisely why we've built cognee—a platform designed to intelligently combine the best aspects of graph databases and vector stores. cognee enriches your data with deeper semantic meaning and context, enabling your LLM-driven applications to generate more insightful and accurate results.
By synergizing the strengths of multiple data structures, cognee ensures you’re using the optimal technology for every task, unlocking hidden value from your data and empowering you to make smarter, relationship-driven decisions.
Curious to check out cognee in action? Contact us! (currently supports Neo4j, Kùzu, FalkorDB, and NetworkX)
Once you see the queries running and returning insights that were previously hidden in messy join-tables, you'll quickly understand why we’re so passionate about what we've built. Till the next reading, happy relationship-building!


