Competition Comparison - Form vs. Function
AI memory systems keep popping up, each one promising “sharper recall,” “richer context,” or “smarter reasoning.” But buzzwords like these don’t make it easy to see what actually sets these tools apart.
When we talk about memory—human or artificial—we’re really dealing with two intertwined questions: how knowledge is organized, and how it’s put to work.
That split maps neatly onto the classic duality of form and function: the structure that holds everything together, and what that structure enables you to do. In AI memory systems, the structure is made up of graphs, embeddings, and connections. These aren’t just implementation details—they’re deliberate design choices about how “remembering” should work.
In this article, we’ll use form and function as practical comparison tools, not as hand-wavy philosophical analogies.
- Form is the layout of knowledge—how entities, relationships, and context are represented and connected, whether as isolated bits or a woven network of meaning.
- Function is how that setup supports recall, reasoning, and adaptation—how well the system retrieves, integrates, and maintains relevant information over time.
Coming up, we’ll stack Mem0, Graphiti, LightRAG, and cognee side by side: see how each builds its graphs (form), how those graphs perform in reasoning and retrieval tasks (function), and which kinds of problems each system is best suited to solve.
Form: How AI Memory Turns Data Into Knowledge
In order to see how AI memory tools structure information from raw input, we fed these same three sentences into Mem0, Graphiti, and cognee:
The structure produced by the system dictates what can later be recalled, how reasoning flows, and how the system treats and evaluates new data.
Graph Structures, Side-by-Side
Below are the knowledge graphs created by Mem0 (left), Graphiti (right), and cognee (bottom).
Mem0 nails entity extraction across the board, but the three sentences end up in separate clusters—no link between Munich and Germany, even though it’s directly stated in the input. Edges explicitly encode relationships, keeping things precise at a small scale but relatively fragmented.
Graphiti pulls in all the main entities too, treating each sentence as its own node. Connections stick to generic relations like MENTIONS or RELATES_TO, which keeps the structure straightforward and easy to reason about, but lighter on semantic depth.
cognee also captures every key entity, but layers in text chunks and types as nodes themselves. Edges define relationships in more detail, building multi-layer semantic connections that tie the graph together more densely.
All three systems missed linking “Dutch people” to the Netherlands, which highlights where off-the-shelf semantic extraction tends to hit its limits without customization.
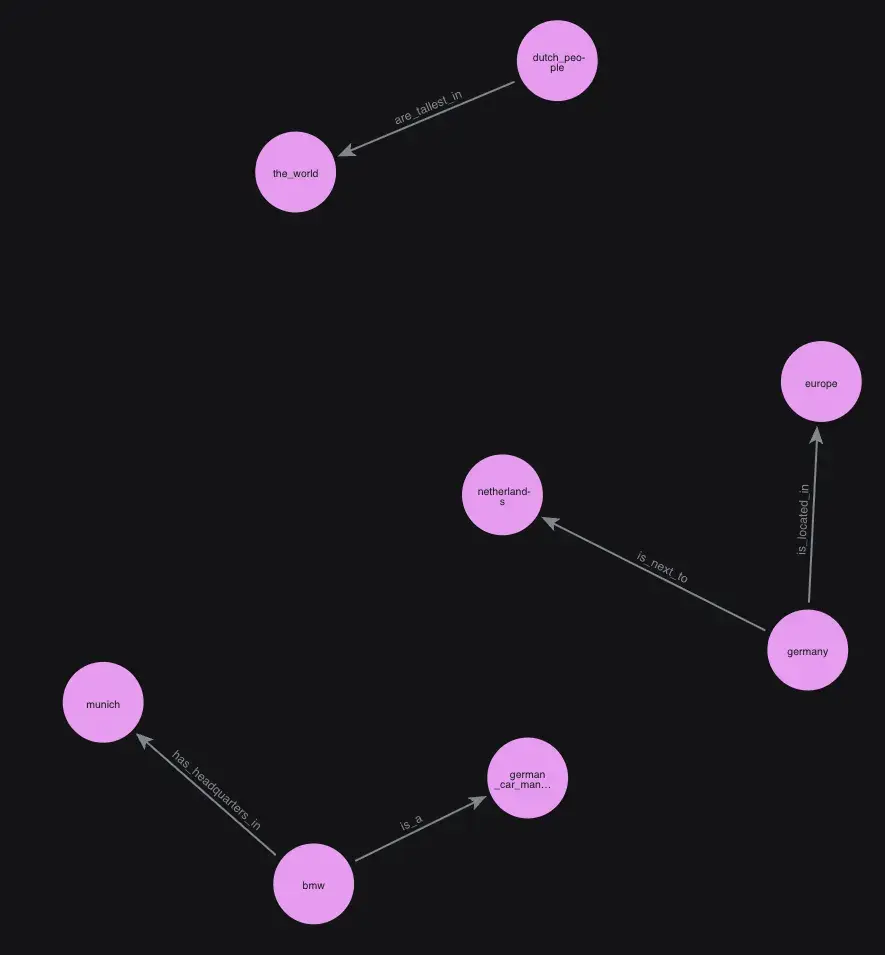
Mem0
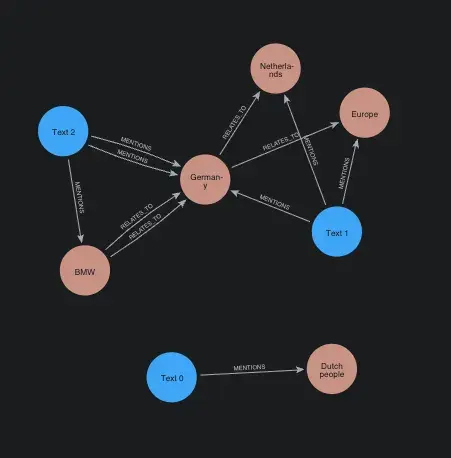
Graphiti
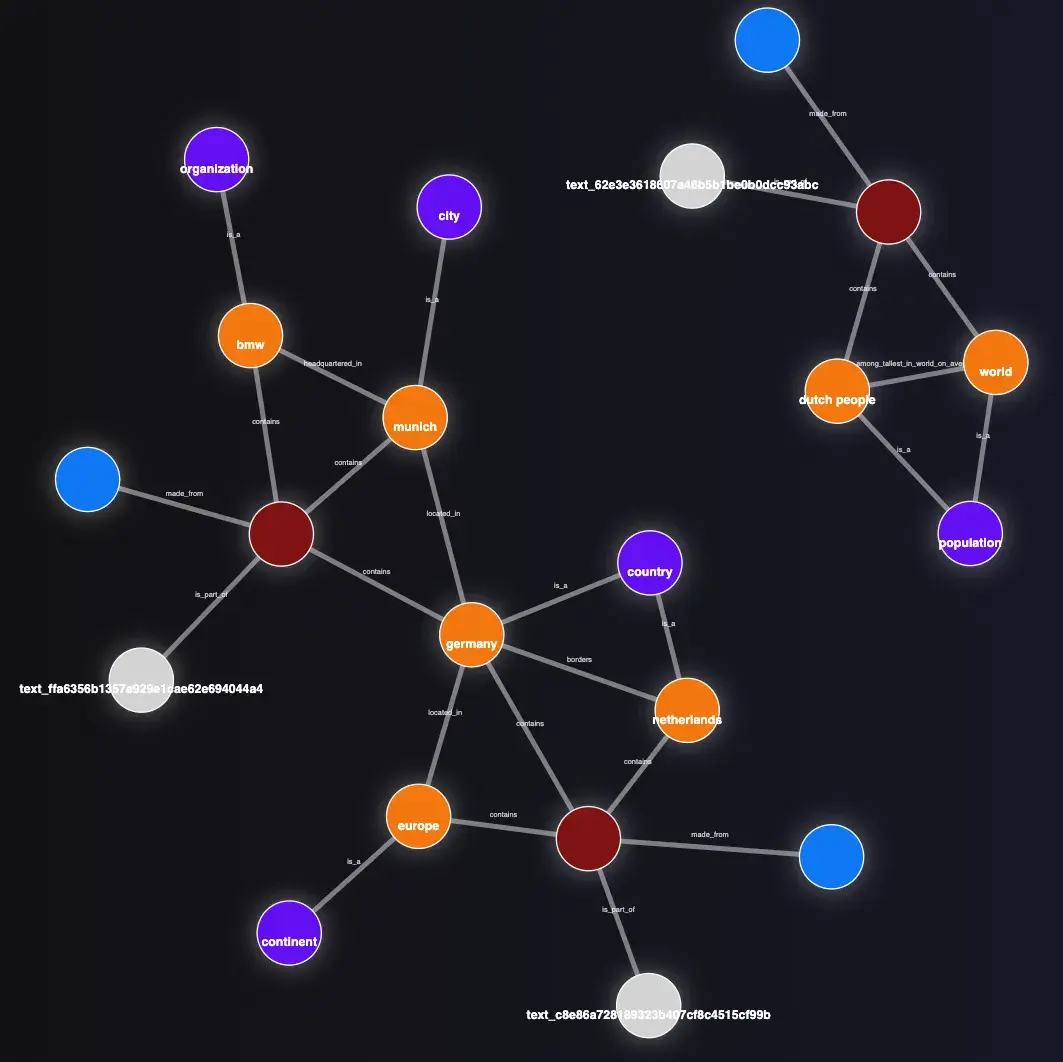
cognee
Each of these graphs reveals a distinct take on knowledge setup. Mem0 goes lean with basic entity nets; Graphiti grounds information in clear, structured ties; and cognee layers in semantics for denser, interconnected views.
Function: What These Graphs Actually Deliver
Benchmarks have that quick-hit appeal—who doesn’t like a single score that cuts through the clutter to announce which AI or memory system is “better?”
However, real-world use is way messier than that, which is why we don’t think single benchmarks are a way to crown winners. Instead, we treat metrics as signals—useful for gauging specific strengths of a system in narrow slices of behavior.
Benchmark performance can still be both informative and illustrative. Informative, because it acts as a numeric proxy for “function” in our form–function framing. And illustrative, because it offers a simple way to compare systems along one dimension that might matter in real use cases.
So while we care most about tangible results in production setups—especially in enterprise AI applications—we include the benchmarks below as one data point, not as a final verdict.
As Joelle Pineau, Chief AI Officer at Cohere, put it around the 45-minute mark in the November 3 episode of “The Twenty Minute VC” podcast:
“You do need to take evaluation seriously in terms of knowledge, but you shouldn't take them seriously in terms of the ultimate goals. So, you know, evaluation, and there's lots of different benchmarks and so on, you have to decide, like, what type of model are you building? What's the characteristics of your system? And then think of evaluations as, like, unit tests for the performance of your system. […] Like, you run through that evaluation and that gives you like a signal of how the system is doing in a particular dimension.
But […] you don't optimize for these. We build AI systems that go into enterprise. None of our clients ask about, like, are you able to win the math Olympiad with this model? That's not what they care about. They care about bringing value to their business. Now, we're curious to know how well we do on math problems because it can be predictive of behavior on other things, but you don't obsess over specific benchmarks. You kind of look at the ROI in terms of what you're trying to build.”
What the Benchmarks Tell Us (and What Don’t They?)
Recently, we ran a comparative evaluation of several leading AI memory systems: LightRAG, Graphiti, Mem0, and cognee. We asked each system to generate answers to 24 HotPotQA questions, then scored their outputs against the original “gold” answers using metrics like Exact Match (EM), F1, DeepEval Correctness, and Human-like Correctness. To account for LLM variance, we ran 45 cycles per system.
Overall, with each system running on its default settings, cognee performed slightly to significantly better across these measurements compared to the other three—particularly strong in Human-like Correctness and DeepEval metrics, which point to solid multi-hop reasoning. LightRAG came close on Human-like Correctness but dipped in precision-focused scores like EM. Graphiti showed reliable mid-range performance across the board, while Mem0 trailed on all metrics, suggesting that its fundamentals work but deeper integration still has room to grow.
None of the systems were tuned specifically for these benchmarks, and each can be configured to improve on particular metrics. Treat these numbers as a snapshot of out-of-the-box behavior. You can explore the exact results below by hovering over the chart.
When Form Fuels Function: Why Custom Stacks Win
If form is the shape of a memory system, then a rigid shape quickly becomes a constraint. Fixed graphs, ingestion paths, or backends limit how well a system can adapt to the workflows it’s meant to support. Most real-world setups need the opposite: a structure that can shift to fit the job.
cognee leans into that flexibility. You can adjust every core piece—from ingestion and storage to entity extraction and retrieval. A pliable form unlocks broader function, and that versatility often matters more in day-to-day use than any single architectural choice. It also opens the door to context engineering, where you refine how layers interact to produce more reliable and scalable outcomes in vertical AI use cases.
This flexibility also changes how we think about comparisons. With so much room to customize, evaluations like the ones above are more like regular health checks than authoritative rankings. They measure a few aspects of systems that can expand in many directions once they’re tailored to real workflows.
In other words, the graph you start with is less important than the graph you can grow into. The real question becomes: which memory layer makes it easiest to evolve with your product, data, and agents?
When Structure Meets Strategy: Choosing the Memory That Fits Your System
The form–function framing may have started as a playful way to describe how memory systems work, but the contrast holds: structure shapes behavior.
Once you see how each system builds and uses its graph, their different strengths start to click into place—and their performance measurements often reflect the shape of the memory they build. Sparse, sentence-level graphs behave differently from dense, layered semantic graphs, and that shows up in how well they handle multi-hop reasoning, noise in the data, or questions that don’t line up neatly with the original inputs.
If you’re evaluating these tools for real-world use, it helps to zoom out from scores and ask a few practical questions:
- Does the form match my data? Can the system comfortably represent documents, events, entities, and relationships the way my product and workflows actually see them?
- Does the function match my workloads? Will this memory layer hold up under agents, orchestration, and changing context windows—or is it tuned mainly for simple RAG-style Q&A?
- Can it evolve with my stack? As new data sources, regulations, or product surfaces appear, will I have to rebuild the graph, or can I adapt ingestion and structure incrementally?
Our most honest advice is to choose the tool that lines up with your goals, constraints, and time horizon—not just the one that tops a chart.
If you want a system that reshapes itself as your needs scale—especially in agentic setups and complex, multi-step workflows—well, we’ve built cognee to be exactly that adaptable memory layer that you can keep refining as your AI products and users become more demanding.

Cognee Raises $7.5M Seed to Build Memory for AI Agents

What OpenClaw is and how we give it memory with cognee
